







Introduction▲
Avant d'aller plus loin, une petite mise en garde d'ordre légal : de nombreux sites interdisent le web scraping dans leurs conditions d'utilisation. Pour éviter tout risque de poursuites, renseignez-vous avant d'extraire automatiquement des données depuis un site web, et respectez la propriété intellectuelle des auteurs.
Si vous avez déjà extrait des données depuis une page web, vous vous dites sans doute « c'est facile, je sais faire ». Vous avez probablement adopté une des approches classiques :
- analyse manuelle : à coups de IndexOf et de Substring, il est bien sûr possible d'arriver au résultat voulu, mais avec cette approche, combien de temps vous faut-il pour extraire de façon fiable un malheureux morceau de texte à un endroit précis de la page ? Trente minutes ? Allez, dix si c'est un cas simple ? Et regardez votre code une fois que vous avez le résultat voulu : est-il facile à lire, est-ce que l'on comprend tout de suite ce qu'il fait ? Sans doute pas… De plus, il y a probablement beaucoup de cas particuliers que vous n'avez pas pensé à gérer et qui sont autant de bugs potentiels ;
- les expressions régulières : ah, les regex… un outil fantastique ! Quand on vient de les découvrir, on a l'impression de pouvoir tout faire avec, on se prend pour un super hérosxkcd: Regular Expressions… Malheureusement, même si l'utilité des regex est indéniable dans de nombreuses situations, elles ne sont tout simplement pas adaptées pour analyser du HTML. Je ne vais pas entrer dans les détails du pourquoi, Jeff Atwood a déjà expliqué celaCoding Horror: Parsing Html The Cthulhu Way beaucoup mieux que je ne saurais le faire. Bien sûr, dans certains cas précis on peut s'en sortir avec des expressions régulières, mais là encore, ce sera au prix d'un code illisible, peu fiable, difficile à déboguer… et au risque d'y laisser sa santéStack Overflow mentaleStack Overflow ;).
En plus des inconvénients déjà cités, ces deux approches ont un défaut majeur : elles reviennent à réinventer la roue, ce qui est généralement considéré comme une mauvaise pratique… L'analyse de code HTML est un problème résolu depuis longtemps, tous les navigateurs web le font !
Le langage HTML est très similaire à XML : on pourrait donc être tenté de l'analyser à l'aide d'une API dédiée à XML (par exemple XmlReader, XmlDocument ou Linq to XML), et dans certains cas cela fonctionnerait… Malheureusement, si on fait exception du cas particulier de XHTML, la plupart des pages HTML ne sont pas des documents XML valides, car HTML est beaucoup moins strict que XML. Un parseur XML normal ne pourra donc pas analyser une page HTML, car il échouera à la première erreur rencontrée (par exemple un attribut sans guillemets ou un élément non refermé).
C'est là qu'entre en jeu HTML Agility PackHTML Agility Pack : c'est une bibliothèque open source qui permet d'analyser le contenu d'une page web via le DOM (Document Object Model), avec une API similaire à Linq to XML, et qui permet aussi l'utilisation de Xpath.
I. Télécharger Html Agility Pack et l'ajouter à votre projet▲
I-A. En utilisant Nuget▲
Si vous utilisez Visual Studio 2010 ou plus récent, le plus simple est d'ajouter le package à votre projet à l'aide du gestionnaire de package Nuget (voir ce tutorielPrésentation du gestionnaire de packages .NET Nuget sur l'utilisation de Nuget). Dans l'explorateur de solutions, faites un clic droit sur le nœud Références de votre projet, et choisissez Manage Nuget Packages (si vous ne voyez pas cette option, c'est que Nuget n'est pas installé ; suivez les instructions du tutoriel sur Nuget pour l'installer).
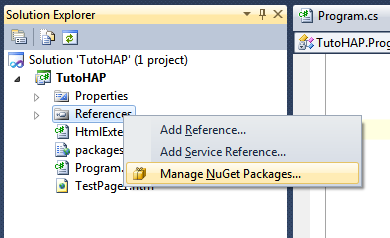
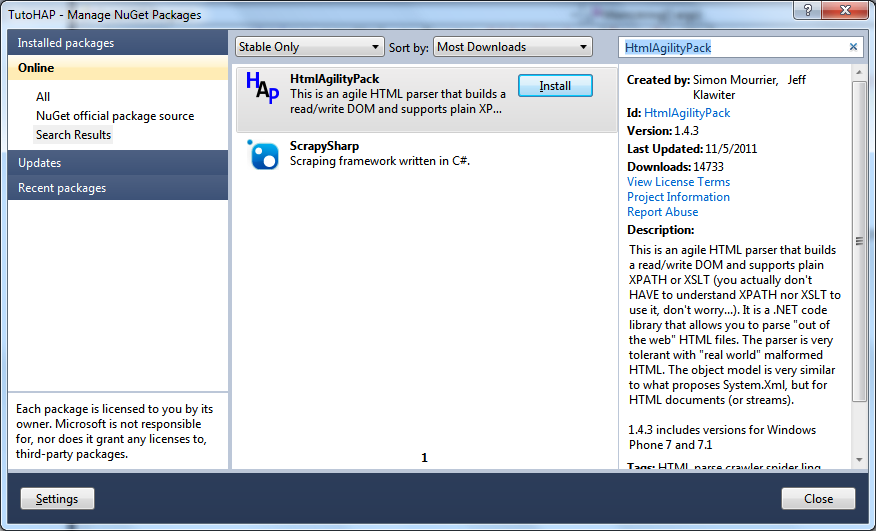
Dans la boîte de dialogue qui s'affiche, sélectionnez la catégorie Online dans la zone de gauche, et tapez HtmlAgilityPack dans le champ de recherche :
I-B. Installation manuelle▲
Téléchargez Nuget depuis le site officiel en cliquant sur Download et décompressez le fichier zip sur votre disque dur. Dans l'explorateur de solution faites un clic droit sur le nœud Références de votre projet, et choisissez Ajouter une référence. Choisissez l'option Parcourir et sélectionnez le fichier HtmlAgilityPack.dll.
II. Charger un document HTML▲
Maintenant que Html Agility Pack (HAP) est ajouté à votre projet, on va pouvoir entrer dans le vif du sujet… On utilisera cette page web comme exemple pour la suite du tutoriel.
Voyons d'abord comment charger un document HTML avec HAP. Commencez par importer le namespace HtmlAgilityPack en ajoutant cette ligne au début de votre fichier de code :
using HtmlAgilityPack;Un document HTML est représenté dans HAP par la classe HtmlDocument (comme c'est original…). Pour charger un fichier XML qui se trouve sur votre système de fichiers local, vous pouvez utiliser le code suivant :
HtmlDocument doc = new HtmlDocument();
doc.Load(cheminDuFichier);Il est également possible de passer à la méthode Load un Stream ou TextReader, et de spécifier l'encodage du fichier. La méthode LoadHtml permet de charger un document HTML contenu dans une chaine de caractères.
Cependant, en pratique le document HTML à charger se trouve généralement sur un site web, il faut donc le télécharger. HAP fournit une classe HtmlWeb pour faciliter le chargement d'un document à partir d'Internet :
string url = "http://tlevesque.developpez.com/tutoriels/dotnet/extraction-donnees-web-html-agility-pack/fichiers/TestPage.html";
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);La méthode Load de la classe HtmlWeb possède également des surcharges permettant de spécifier un utilisateur et un mot de passe, ou encore un proxy. Cela devrait couvrir la plupart des cas d'utilisation ; si vous avez besoin de plus de contrôle sur la requête HTTP, il est bien sûr possible d'utiliser WebClient ou HttpWebRequest, et de charger le document à partir du flux de la réponse.
III. Extraire des informations▲
Maintenant que le document HTML est chargé, voyons comment on peut en extraire des données. HAP permet de parcourir le DOM (Document Object Model), c'est-à-dire l'arborescence du document. Le DOM est constitué de « nœuds » imbriqués, qui représentent des éléments (ou balises) HTML, du texte, ou des commentaires. Dans HAP, les nœuds sont représentés par la classe HtmlNode. Le nœud racine représente le document lui-même ; on y accède via la propriété DocumentNode de HtmlDocument. À partir de cette racine, on va « descendre » dans le document pour trouver les nœuds qui nous intéressent.
III-A. La méthode Element▲
Commençons par un cas simple : récupérer le titre de la page. Cette information se trouve dans la balise <title>, qui se trouve dans la balise <head>, elle-même située dans la balise <html> :
En partant de la racine, on va donc chercher l'élément html, puis l'élément head, puis l'élément title. La méthode Element de HtmlNode permet d'obtenir le premier élément enfant qui a le nom spécifié à partir de son parent. Par exemple, pour récupérer l'élément html, on va faire comme ceci :
var htmlElement = doc.DocumentNode.Element("html");Puisque la méthode Element renvoie également un HtmlNode, on peut chaîner les appels pour obtenir directement l'élément voulu :
var titleElement =
doc.DocumentNode
.Element("html")
.Element("head")
.Element("title");Une fois qu'on a trouvé l'élément recherché, il suffit de récupérer son texte avec la propriété InnerText :
if (titleElement != null)
{
string title = titleElement.InnerText;
Console.WriteLine("Titre: {0}", title);
}
else
{
Console.WriteLine("Pas de titre");
}Notez que la méthode Element renvoie null si l'élément recherché n'existe pas : il faut donc vérifier si l'élément existe avant d'essayer de l'utiliser. D'ailleurs, le code précédent n'était pas très sûr, puisqu'il ne vérifiait pas l'existence des éléments html et head. En pratique, tous les documents HTML devraient comporter ces balises, donc le risque est limité…
III-B. La méthode Elements▲
Supposons maintenant qu'on veut récupérer tous les éléments <h2> (titre de niveau 2) qui se trouvent directement dans le corps (<body>) de la page.
Récupérons d'abord l'élément <body> :
var body =
doc.DocumentNode
.Element("html")
.Element("body");Mais maintenant, comment récupérer tous les enfants <h2> de cet élément ? La méthode Element ne convient pas, car elle renvoie un seul élément… on va donc utiliser Elements, qui fait presque la même chose, mais permet de récupérer plusieurs éléments :
var titles = body.Elements("h2");
foreach (var title in titles)
{
Console.WriteLine(title.InnerHtml);
}Notez qu'on a utilisé ici InnerHtml et non InnerText. La différence entre les deux est que InnerHtml renvoie le code HTML contenu dans l'élément, alors que InnerText ne renvoie que du texte (les balises HTML sont enlevées).
Contrairement à Element, qui renvoie null si l'élément n'est pas trouvé, Elements renvoie une séquence qui ne contient aucun élément.
Notez que Element et Elements ne cherchent que dans les enfants directs de l'élément actuel : les enfants des enfants ne sont pas trouvés. Par exemple, un élément <h2> placé dans un <div> et non directement dans <body> ne serait pas trouvé par le code précédent.
III-C. La méthode Descendants▲
Essayons maintenant de récupérer les textes de tous les liens (<a>) qui se trouvent dans la page, quel que soit leur niveau. On a vu plus haut que Elements ne cherche que parmi les enfants directs ; si on ne sait pas à l'avance quels sont les parents des éléments recherchés, il faut donc utiliser autre chose… C'est là qu'intervient la méthode Descendants : elle cherche récursivement parmi tous les descendants d'un élément, quel que soit leur niveau :
var links = doc.DocumentNode.Descendants("a");
foreach (var link in links)
{
Console.WriteLine(link.InnerText);
}Ici on a utilisé la surcharge de Descendants qui prend en paramètre le nom de la balise, car on cherche seulement les liens. Sachez qu'il existe aussi une surcharge sans paramètre, qui récupère tous les descendants, quel que soit leur nom.
III-D. La propriété Attributes et la méthode GetAttributeValue▲
Voyons maintenant comment récupérer les adresses des liens de la page. L'adresse d'un lien ne se trouve pas dans le contenu de l'élément <a>, mais dans un attribut href. Pour récupérer la valeur d'un élément, on peut utiliser la propriété Attributes, qui renvoie une collection des attributs de l'élément, ou la méthode GetAttributeValue, qui renvoie directement la valeur de l'élément voulu.
Voilà comment utiliser Attributes :
var links = doc.DocumentNode.Descendants("a");
foreach (var link in links)
{
var href = link.Attributes["href"];
if (href != null)
Console.WriteLine(href.Value);
}Attributes renvoie une collection clés/valeurs d'objets HtmlAttribute. Attributes["x"] renvoie l'attribut x. Si l'attribut x n'existe pas, alors Attributes["x"] renvoie null. Pour obtenir la valeur d'un attribut, on utilise la propriété Value de l'objet HtmlAttribute.
Dans certains cas, il est plus pratique d'utiliser la méthode GetAttributeValue, qui prend en paramètre le nom de l'attribut et la valeur par défaut qui sera renvoyée si l'attribut n'existe pas :
var links = doc.DocumentNode.Descendants("a");
foreach (var link in links)
{
string href = link.GetAttributeValue("href", "(pas d'adresse)");
if (href != null)
Console.WriteLine(href);
}Notez que, puisque Descendants renvoie une collection de HtmlNode, il est possible d'utiliser Linq pour extraire directement les adresses :
var linkAddresses =
from link in doc.DocumentNode.Descendants("a")
select link.GetAttributeValue("href", "(pas d'adresse)");Ou encore, si on veut seulement les liens qui ont vraiment une adresse :
var linkAddresses =
from link in doc.DocumentNode.Descendants("a")
let href = link.GetAttributeValue("href", null)
where href != null
select href;III-E. La méthode GetElementById▲
Bien souvent, si on sait exactement ce qu'on cherche dans le document, on n'a pas vraiment besoin de le parcourir en entier ; si l'élément recherché a un identifiant, on peut le récupérer directement à partir de cet identifiant, grâce à la méthode GetElementById du HtmlDocument.
Par exemple, si on veut récupérer le tableau dont l'identifiant est Contacts, on peut faire comme ceci :
var table = doc.GetElementbyId("Contacts");III-F. La méthode Ancestors et la propriété ParentNode▲
Jusqu'ici, on a parcouru le document HTML en « descendant » depuis la racine du document. Mais si on voulait faire le contraire ? Par exemple, si on voulait savoir quel est l'élément parent de la table Contacts (en l'occurrence l'élément <body>), on pourrait utiliser la propriété ParentNode :
var table = doc.GetElementbyId("Contacts");
var parent = table.ParentNode;Il existe aussi une méthode Ancestors qui permet de récupérer tous les éléments « au-dessus » de l'élément courant qui ont le nom spécifié :
// Récupère tous les <div> dans lesquels
var table = doc.GetElementbyId("Contacts");
var parentDivs = doc.Ancestors("div") ;Dans la version actuelle de HAP (1.4.6), il y a un bug dans la surcharge de Ancestors qui ne prend pas de paramètre : elle ne renvoie pas le parent direct, mais seulement les ancêtres à partir du grand-parent. Une solution est d'utiliser à la place AncestorsAndSelf.Skip(1).
III-G. Utilisation de Xpath▲
L'API de HTML Agility Pack est très simple à utiliser, notamment grâce à sa similitude avec Linq to XML. Cependant, certaines personnes préfèrent utiliser XPath ; et ça tombe bien, HAP supporte aussi cette méthode !
L'API XPath est similaire à ce qu'on trouve dans la classe XmlDocument :
- une méthode SelectSingleNode pour récupérer un élément unique :
// Récupération de la table dont l'id est 'Contacts'
var table = doc.DocumentNode.SelectSingleNode("//table[@id='Contacts']");- une méthode SelectNodes pour récupérer une collection d'éléments :
// Récupération des liens qui ont la classe 'toto'
var links = doc.DocumentNode.SelectNodes("//a[@class='toto']")Je n'entrerai pas dans les détails de la syntaxe XPath, puisque c'est standard et qu'il y a déjà de nombreux tutoriels à ce sujet.
III-H. Un exemple (un peu) plus élaboré▲
Maintenant qu'on connaît les principales méthodes qui permettent de retrouver et d'extraire des informations dans une page web, mettons cela en pratique avec une tâche un peu plus complexe… À la fin de la page d'exemple se trouve un tableau avec une liste de contacts. Supposons qu'on souhaite extraire les contacts pour les mettre dans une liste d'objets.
Définissons tout d'abord une classe Contact :
class Contact
{
public string LastName { get; set; }
public string FirstName { get; set; }
public int Age { get; set; }
}Observons ensuite la structure HTML de la table :
<table id="Contacts" border="1">
<thead>
<tr>
<th>Nom</th>
<th>Prénom</th>
<th>Age</th>
</tr>
</thead>
<tbody>
<tr>
<td>Tartempion</td>
<td>Gérard</td>
<td>60</td>
</tr>
<tr>
<td>Abitbol</td>
<td>George</td>
<td>42</td>
</tr>
<tr>
<td>Potter</td>
<td>Harry</td>
<td>17</td>
</tr>
<tr>
<td>Wayne</td>
<td>Bruce</td>
<td>30</td>
</tr>
</tbody>
</table>On note que la table a un identifiant, ce qui va simplifier un peu la recherche ; on peut récupérer la table à l'aide de GetElementById :
var table = doc.GetElementbyId("Contacts");Puisque la table utilise les balises <thead> et <tbody>, on peut facilement éliminer la ligne d'en-tête en ne prenant en compte que les lignes (<tr>) qui se trouvent dans <tbody> :
var rows = table.Element("tbody").Elements("tr");Maintenant que nous avons les lignes, il ne nous reste qu'à extraire les contenus des cellules (<td>) de chaque ligne pour construire nos objets Contact. On peut facilement le faire à l'aide d'une requête Linq :
var contacts =
from r in rows
let values = r.Elements("td").Select(c => c.InnerText).ToArray()
select new Contact
{
LastName = values[0],
FirstName = values[1],
Age = int.Parse(values[2])
};Affichons maintenant le résultat pour vérifier :
foreach (var c in contacts)
{
Console.WriteLine(
"{0} {1} ({2} ans)",
c.FirstName,
c.LastName,
c.Age);
}Et on obtient bien la même chose que dans le tableau :
Gérard Tartempion (60 ans)
George Abitbol (42 ans)
Harry Potter (17 ans)
Bruce Wayne (30 ans)
Essayez maintenant d'imaginer le code que vous auriez dû écrire pour faire la même chose avec des expressions régulières ou des manipulations de chaines. Ça aurait sans doute pris un temps fou, le code serait illisible, et contiendrait probablement des bugs…
Conclusion▲
Ainsi se termine cette présentation de HTML Agility Pack. J'espère que le dernier exemple vous aura convaincu de l'intérêt d'utiliser cet outil pour extraire des données d'une page web. Notez que, bien que l'article n'ait pas abordé cet aspect, HAP permet également de modifier des pages HTML. Ça pourra éventuellement faire l'objet d'un futur article !
Remerciements▲
Je tiens à remercier Chtulus et Jean-Michel Ormes pour leurs remarques, ainsi que Torgar pour la correction orthographique.